What are we doing here?
This is the first part of a two-part series covering 1) CI (continuous integration/build) and 2) CD (continuous deployment/release) for Visual Studio SQL Server Database and Integration Services project types on the VSTS (Visual Studio Team Services) platform.
Some background
The Visual Studio business intelligence (SSIS, SSRS, SSAS) and database projects types have long been the red headed step child of the Visual Studio ecosystem. Huge strides have been made in recent years but there are still some impediments, one of which is creating CI/CD pipelines in Visual Studio Team Services.
Don't fret
While it's not as straightforward as say a ASP.NET web application, with just a little finessing it's not overly difficult to build and deploy SQL Server Database and Integration Services project types. If you're familiar with creating VSTS build and release definitions it probably wouldn't take you too long to get it figured out. If you are new to this functionality it can definitely be a bit overwhelming. Hence, this step-by-step guide to standing up a basic VSTS build definition that includes both database and SSIS projects.
Assumptions (you know what they say...)
The following steps assume that 1) you have a
VSTS account 2) a VSTS collection, 2) a VSTS project within the collection and 3) have a source control repository in VSTS Git, TFVC, GitHub, Subversion, Bitbucket Cloud, or Git (not necessarily hosted by VSTS).
This walk through will use an open source project called
SSISProjectWeaver that is hosted on GitHub (using a different repository type requires little, if any changes). It's not necessary to know the details of the SSISProjectWeaver project other than that it contains a SQL Server Database project and two Integration Services projects.
<plug>If you're starting a new SSIS project it's worth checking out
SSISProjectWeaver as it's a 100% non-invasive ETL framework that provides metadata-driven parallelism and dependencies between any two packages or groups of packages, extensive logging, reporting and dashboarding, alerting, and a bunch more. It's easy to set up and has been proven in large organizations with hundreds of packages running a day. You don't have to modify your existing code and if you don't like it you just stop using it. Nothing will have to change with your existing packages.
</plug>
Let's do it
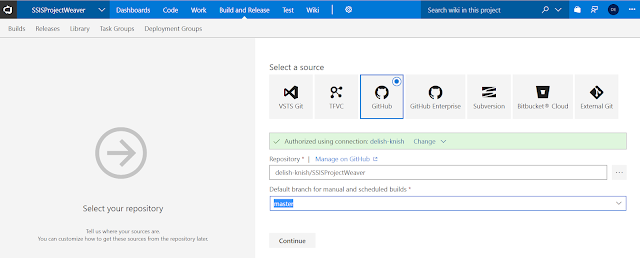
- Open you VSTS project and click on the Build and Release tab.
- Choose your source. For this example we are going to use GitHub.
- Once you've connected to the repository, select the branch that you want to build and click Continue.
- In the top right-hand corner under Select a template, click Empty Process. This will start us off with a blank build definition.
Name your build definition appropriately and then choose the Agent queue. In this example we are using a Hosted VS2017 queue. Depending on your project you might want to use a local/on-premise build agent of VS2015. It all depends on your project types, versions, dependencies, etc.
- Before we define our build tasks let's create some variables. Click on the Variables tab and create the BuildConfiguration and BuildPlatform variables along with their corresponding default values.
Navigate back to the Tasks tab and click the + next to Phase 1. Search for and choose the Visual Studio Build task. This task will use the out-of-the-box msbuild template for building SQL Server database projects with a .dacpac as the build output.
Change the Display name to something meaningful.
Choose the SQL Server database project or solution to build.
Choose the version to build.
Use the newly created variables for the Platform and Configuration properties.
Save the task.
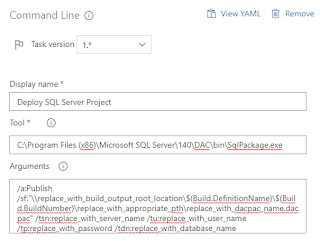
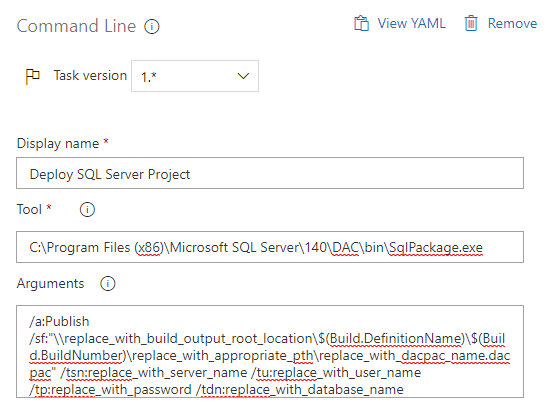
Navigate back to the Tasks tab and click the + next to Phase 1. Search for and choose the Command Line task. We will use this task as a workaround to a lack of an msbuild template for SSIS projects by calling invoking devenv to build the projects.
Change the version to 2.*(preview). This version allows multi-line commands similar to a .bat file.
Change the Display name to something meaningful.
Enter the following text into the Script box. The first 8 lines just echo (print line) info that is useful for debugging. The last line is the actual command that is being executed.
echo BuildShare: $(BuildShare)
echo Agent.BuildDirectory: $(Agent.BuildDirectory)
echo Build.SourcesDirectory: $(Build.SourcesDirectory)
echo Build.ArtifactStagingDirectory: $(Build.ArtifactStagingDirectory)
echo System.DefaultWorkingDirectory: $(System.DefaultWorkingDirectory)
echo BuildConfiguration: $(BuildConfiguration)
echo BuildPlatform: $(BuildPlatform)
echo Command: "C:\Program Files (x86)\Microsoft Visual Studio\2017\Enterprise\Common7\IDE\Devenv.com" "$(Build.SourcesDirectory)\your_project_or_solution_name.(sln|proj)" /build $(BuildConfiguration)
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Enterprise\Common7\IDE\Devenv.com" "$(Build.SourcesDirectory)\your_project_or_solution_name.(sln|proj)" /build $(BuildConfiguration
Save the task.
Click on the Triggers tab and enable continuous integration. This will enable VSTS to execute this build definition each time code is committed to your source control repository.
Test the build definition by clicking on Queue.
Assuming your build was successful, you now have the CI half of your CI/CD pipeline and can auto-notify the world when one of your co-workers breaks the build!
Wrap Up
When it comes to technology, nothing is ever as simple as it appears. The SSISProjectWeaver solution is pretty straightforward in terms of code and dependencies. It's T-SQL and SSIS packages with no external dependencies. Building it is is very straightforward as you can see above. However, many projects are much more complex and require more complex configurations to set up a build definition. For example, the first time I created a build definition with an SSIS project it failed because I had references to 3rd party components. Of course Microsoft doesn't know I am using those components so it's not on their hosted build servers. To make it work I had to give up the convenience of using a hosted build server and stood up my own build server with all the necessary components. Food for thought. Don't be discouraged if you hit a few stumbling blocks on your way to automated build bliss!
Stay tuned for part two which will cover CD (continuous deployment) and will walk you through getting your code deployment automated.
As always, if you have any questions feel free to drop me an email at david@elish.net.